Overhauling a Major Health Data Platform

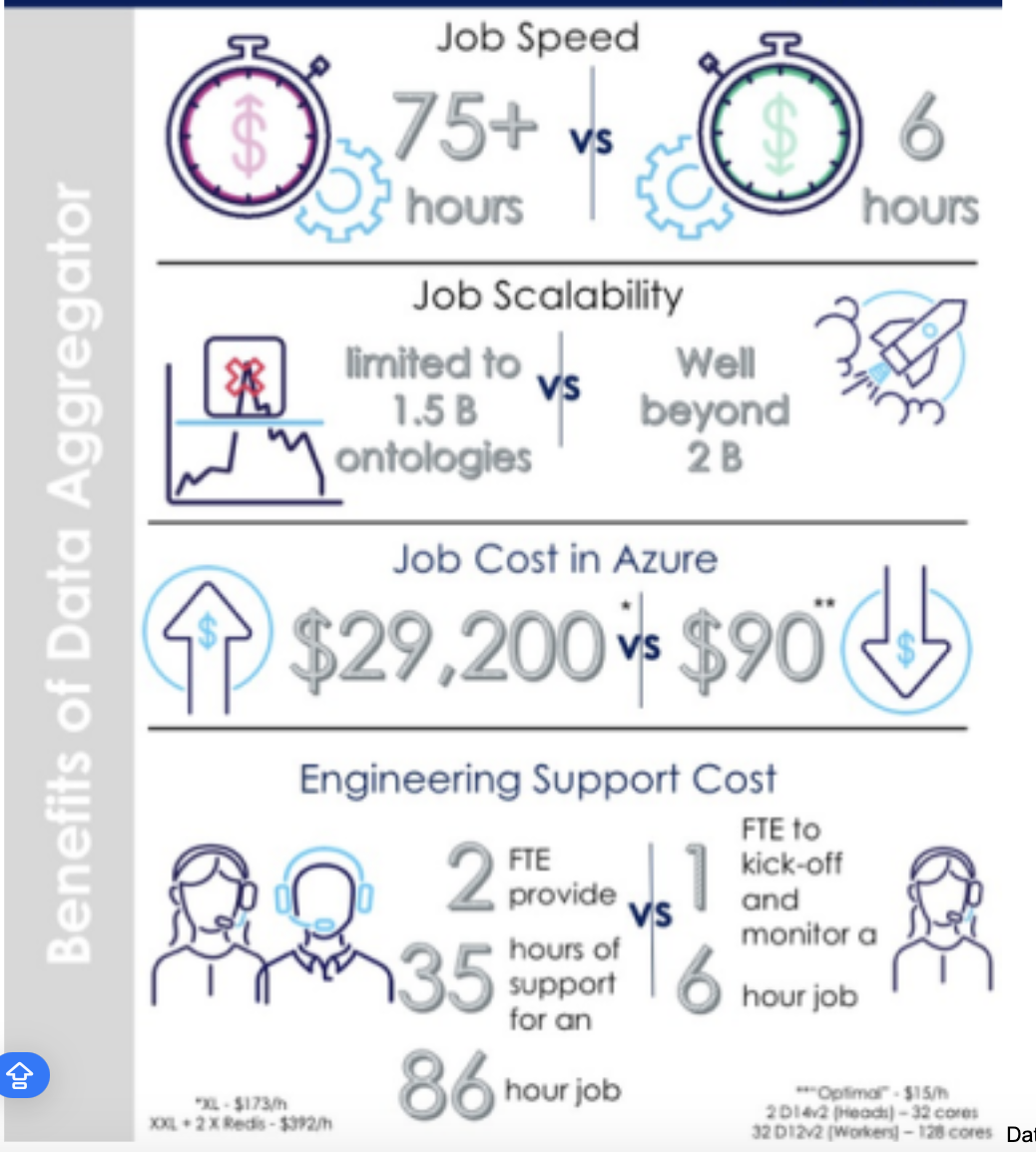
The existing data platform was highly unstable and frequently experienced failures. Job runs would often crash and require restarts, even after running for multiple days. This instability resulted in significant costs, amounting to tens of thousands of dollars. Additionally, job run times consistently exceeded SLA thresholds and reached the maximum capacity for scaling ontologies. To address these challenges, the entire conveyor data platform was slated for replacement with a faster, more scalable, stable, and cost-efficient Data Aggregator.
PROJCT GOAL
Reduce the average customer job run time (across all environments)
Reduce the average customer job run cost (across all environments)
Support more job runs within agreed SLAs
Provide incremental value in data delivery to customers
Remain aligned with IHDP
Current runtime was 86 hours on Extra Large cluster ($16.91/h) plus Redis cluster ($18.35/h) = $3032 per run (in best case if nothing failed and job wasn’t re-run). My estimation of proposed solution run is 2-4 hours on Medium Cluster ($14.95/h) – total cost of run 30-60$
Target Go live in Production: Go-live by the end of the fiscal year.
Team: Four development teams and one DevOps team were involved.
TECHNICAL PLAN
1. Development
1.1 Functionality
1.1.1 Identity
1.1.2 Terminology
1.1.3 Curation
1.1.4 Representation
1.1.5 Representation Curation (Linked Resources, Aggregation)
1.1.6 Representation Terminology
1.1.7 Packaging CSV
1.1.8 Packaging OSDB
1.1.9 Logging - Galaxy
1.1.10 Job Main Function
2. Unit Testing
2.1 Code Coverage
2.1.1 Identity
2.1.2 Terminology
2.1.3 Curation
2.1.4 Representation
2.1.5 Representation Curation
2.1.6 Representation Terminology
2.1.7 Packaging CSV
2.1.8 Packaging OSDB
3. Deployment
3.1 Build & Deploy Job
3.2 Deploy Dependencies
3.2.1 Nick Names File
3.2.2 Terminology Mappings
3.2.3 Configuration Files
4. Integration Testing
4.1 Conveyor Tests
4.1.2 Integrate Data Aggregator
4.1.3 Representation Mappers
4.1.4 Representation for Profiling
4.3 E2E Tests
4.3.1 Teamcity Project
4.3.2 Representation Mappers
4.3.3 Make E2E tests green
4.4 Crypto Internal QA
5. Documentation
5.1 Readme
5.2 System Failure Analysis
6. Performance Testing
6.1 Refresh Sentara Data
6.2 Run Data Aggregator
7. Scheduling
7.1 Runbook Setup
7.2 Job Configuration
8. Customer Rollout
8.1 Promote Conveyor Tests to Stage
8.2 Promote E2E tests to Stage
8.3 Crypto Internal Tests to Stage
8.4 Promote code to INT
8.5 Run Sentara Job in INT
8.6 Run E2E in INT
8.7 Refactor SSIS Package
8.9 Internal UAT
8.10 Promote to Prod
8.11 Run E2E in Prod
8.12 Repartition Sentara Data on Prod
8.13 Run Sentara Job on Prod
8.14 Intermal UAT in Prod
9. Knowledge Transfer and Handoff
9.1 Runbooks
9.2 Monitoring
9.3 Deployment
9.4 Failure Analysis
RESULTS
Job Run Time
Cost Savings

Over 1,000 Engineering development hours across 5 teams